










AIの進化は目覚ましく、その一環としてOpenAIはQ*プロジェクトを推進しています。このプロジェクトは、人工知能の潜在能力をさらに引き出し、新たな技術革新への扉を開くことを目指しているのです。しかし、その進化にはリスクも伴います。人類にとってAIは助けとなるだけでなく、取り扱いを誤ると脅威にも変わり得るため、その重要性について理解を深めることが急務です。この記事では、Q*プロジェクトが何を目指し、どのようなポイントが注目されるべきかを解説します。
OpenAIのQ*プロジェクトとは?
OpenAIのQ*プロジェクトは、人工知能モデルの進化における技術的なブレイクスルーを目指すAI研究の取り組みです。このプロジェクトは、AIが数学の問題を解決するための推論能力を向上させることを目的としています。Qプロジェクトの概要としては、既存のQ*プロジェクトの枠組みを超え、複雑な問題に対するAIの理解度を深めることに重点を置いています。
Q*プロジェクトの目的は、AIが人間のように論理的思考を行い、未知の問題への適応能力を持つようにすることです。この目標に向けて、OpenAIは様々な学習アルゴリズムとニューラルネットワークの開発に注力しており、その結果が期待されています。
Qスターが注目される理由は、人類の知識の境界を拡張する可能性があるからです。AIが数学やその他の学問分野で新たな解を見つけ出すことができれば、科学や工学の進歩に大きく貢献することができるでしょう。また、このプロジェクトは、AIの倫理的な側面や安全性にも配慮しながら進められており、人類にとっての利益を最大化することを目指しています。
Q*プロジェクトの概要
Q*プロジェクトは、人工知能の新たな地平を開くことを目的とした野心的な取り組みです。OpenAIによって進められるこのプロジェクトは、未解決の数学問題に挑む能力を持つAIモデル、Q*(キュースター)の開発に注力しており、従来のAIでは難しいとされていた小学校レベルの数学問題を解くことに成功しています。この技術的ブレイクスルーは、AIが推論し、ステップバイステップで問題を解析する能力を持つことを意味します。
しかし、Q*の進化は、その潜在的な危険性にも注目が集まっています。OpenAIの一部スタッフが、Q*が人類に脅威をもたらす可能性を指摘し、警告を発しているとの報道もありました。そのため、プロジェクトチームはAIの安全性を最優先に考慮しながら開発を進めています。
Q*の推論能力は、数学問題を解くだけに留まらず、より広範な応用への可能性を秘めています。例えば、結婚式の席次決めのような複雑なロジスティック問題にも対応可能です。また、Tree of Thoughtsという新しいアプローチにより、AIが異なる方向に分岐する推論チェーンを体系的に探索することが可能になっています。
このような進歩は、AIが一般的な推論能力を持つことへの重要な一歩となり、将来的には人間のような創造的な問題解決能力をAIにもたらすかもしれません。Q*プロジェクトは、AI研究の新しいフロンティアを拓くことで、未来の技術革新に大きな影響を与えることが期待されています。
Q*プロジェクトの目的とは?
OpenAIが進めるQ*プロジェクトは、人工知能モデルの新たな地平を開く試みです。このプロジェクトの概要として、Q*は、高度な推論能力と学習機能を持つAIの開発を目指しています。その目的は、AI研究における技術的なブレイクスルーを実現し、様々な分野での問題解決能力を大幅に向上させることにあります。
Q*プロジェクトが注目される理由は、その革新性と、人類を脅かす可能性を含むリスクへの深い洞察にあります。プロジェクトは、AIの倫理的な側面と安全性にも配慮しながら進められており、AIが人間社会に積極的に貢献するための基盤を築くことを目標としています。
Qスターが注目される理由
OpenAIが開発したQ*(キュースター)は、以前には不可能だった数学問題を解く能力を持つと報じられ、AI技術の新たな地平を切り開く可能性があります。この新しいモデルは、従来のAIが苦手としていた複雑な推論や計算を、ステップバイステップで処理することによって解決します。この進歩は、私たちが知るAIの限界を押し広げ、より高度な認識能力を持つAIの実現に一歩近づけるかもしれません。
Q*の能力は、単に数学問題を解くことだけに留まらず、その推論プロセスを小さなステップに分けることで、言語モデルがより複雑な問題に取り組むための基盤を築くことにも寄与しています。このアプローチは、Googleの研究者たちによっても支持され、大規模言語モデルが一つずつステップを踏むことで、より正確な結果を導き出せることが示されています。
また、Q*の開発においては、数学問題を解決する際に発生する中間ステップを評価し、正しい方向に進んでいるかを判断する検証者モデルの役割が重要です。この検証者モデルは、可能な解答の中から最も正確と思われるものを選び出すことで、AIの推論能力をさらに高めています。
Q*の注目すべき点は、NP困難問題のような複雑な問題に対してもアプローチを試みていることです。これらの問題には直接的な解法が存在せず、可能な解の組み合わせを試す必要があります。Q*は、このような問題に取り組む際に、バックトラッキングや異なる推論チェーンを探索することで、新たな解決策を見つけ出す可能性を秘めています。
OpenAIとDeepMindが公開した研究からは、AIがより高度な推論タスクをこなすために、検索ツリーやグラフなどの戦略を使って、複数の方向から問題にアプローチすることの重要性が浮き彫りになっています。これにより、AIは自身の推論能力を向上させるための新たな手法を探索し、人間のように柔軟な思考を行うことが期待されています。
Q*は、AI技術の未来において、人工知能が直面する課題に対して新しい解決策を提供し、AIの潜在能力を広げるための重要なステップと見なされています。このような進歩が、AIが人間の知能を模倣し、さらには超える日をもたらすかもしれません。
OpenAIについて
OpenAIは、人工知能の研究と開発を行う非営利団体であり、そのミッションは安全で強力な人工知能の利益を全人類と共有することにあります。技術的なブレイクスルーを通じて、人工知能が人類を脅かす可能性に対する解決策を模索し、その推論能力を活用して人間の生活を向上させることを目指しています。
リーダーシップチームには、サム・アルトマン、イーロン・マスク、グレッグ・ブロックマンなど、テクノロジー業界で著名な人物が名を連ねています。彼らはOpenAIの指針となる哲学と倫理観を形作り、大規模言語モデルやその他のAI技術の開発を推進しています。
OpenAIはQ*プロジェクトを含む多くの注目すべきプロジェクトを手がけており、それらはAIの進化において重要な役割を果たしています。これらのプロジェクトは、AIが持つ可能性を最大限に引き出しつつ、リスクを管理するための研究開発にも貢献しています。
OpenAIのミッションとは?
OpenAIは、人工知能の安全で利益をもたらす研究開発を推進することをミッションとしています。この組織は、AIが人類にとって有益な方法で進化することを目指し、OpenAIスタッフが技術的なブレイクスルーを目指して日々研究に取り組んでいます。特に、大規模言語モデルの開発は、推論能力や自然言語処理の向上に寄与しており、AI研究の最前線を走っています。
さらに、OpenAIはAIが人類を脅かす可能性にも注視しており、その安全性を確保するためのガイドラインの策定にも力を入れています。リーダーシップチームは、AI技術の進歩に伴う倫理的な問題や社会への影響を考慮し、責任ある研究を推進しています。
OpenAIのプロジェクトは、単に技術的な発展だけではなく、AIが人間社会にどのように役立つかを探求するものも多く含まれています。これらのプロジェクトから生まれる成果は、AIのポジティブな使用を促進し、将来的なリスクを最小限に抑えるための基盤となるでしょう。
OpenAIのリーダーシップチーム
OpenAIは、強力な人工知能(AI)の開発を目指し、人類全体の利益を追求することをミッションとしています。この組織は、技術的なブレイクスルーを達成するため、高度な推論能力を持つAIの研究に専念しており、その過程で人類を脅かす可能性のあるリスクを最小限に抑えることにも注力しています。OpenAIスタッフは、多様なバックグラウンドを持つ専門家集団で構成され、取締役会の指導の下、AIの安全性と倫理性を確保するための方針を策定しています。OpenAIのリーダーシップチームは、Qスター(Q*)と呼ばれるプロジェクトを含む、いくつかの先進的な取り組みを推進しており、その成果は世界中の研究者や開発者に影響を与えています。OpenAIは、AI分野でのリーダーとして、技術革新の最前線を走り続けています。
OpenAIの他の注目プロジェクト
OpenAIは、人工知能研究を推進し、技術的なブレイクスルーを目指す組織です。そのミッションは、友好的なAIの利益を全人類と共有することを目的としています。OpenAIのリーダーシップチームには、イーロン・マスクやサム・アルトマンなど、著名な起業家や学者が名を連ねています。
注目すべきQ*プロジェクトは、推論能力や数学の問題を解決するための人工知能モデルの開発に焦点を当てています。これらのプロジェクトは、AI研究における新たな地平を開き、将来的には教育や科学分野での応用が期待されています。OpenAIの取り組みは、人間の知識を拡張し、より良い未来を築くための重要なステップとなっています。
Q*プロジェクトを理解するための参考資料
Q*プロジェクトに関する興味深いレポートをティモシー・B・リー氏がまとめました。それを意訳して紹介します。
ティモシー・B・リー氏は、技術、経済、および公共政策について10年以上にわたり執筆してきたジャーナリストです1。彼はFull Stack EconomicsとUnderstanding AIというニュースレターを立ち上げる前に、ワシントンポスト、Vox.com、Ars Technicaで記者として活動していました。また、彼はプリンストン大学でコンピュータサイエンスの修士号を取得しています。
BingAIより
OpenAIのQ*プロジェクトに関する激しい噂の背後にある実際の研究
11月22日、OpenAIがCEOのサム・アルトマンを解任(その後再雇用)した数日後、The InformationはOpenAIが技術的なブレイクスルーを達成し、「はるかに強力な人工知能モデルを開発する」ことができるようになったと報じました。Q(キュースターと発音されます)と名付けられた新モデルは、「以前に見たことのない数学の問題を解決する」能力があるとされています。
ロイターも似たような記事を掲載しましたが、詳細は不明瞭でした。
両メディアは、この推定されるブレイクスルーをアルトマンの解任決定と関連付けています。ロイターは、複数のOpenAIスタッフが取締役会に「人類を脅かす可能性がある強力な人工知能の発見」について警告する手紙を送ったと報じました。しかし、「ロイターはその手紙のコピーを確認することができなかった」とし、その後の報道ではアルトマンの解任とQに関する懸念との関連は示されていません。
The Informationは、今年初めにOpenAIが「基本的な数学の問題を解決できるシステム」を構築したと報じています。これは、既存のAIモデルにとって難しい課題です。ロイターはQを「小学生レベルの数学を行う」と表現しています。
ただちに憶測に飛びつくのではなく、私は数日間読書をすることにしました。OpenAIは、推定されるQのブレイクスルーに関する詳細を公開していませんが、小学校レベルの数学の問題を解決するための努力に関する2つの論文を公開しています。また、OpenAIの外部の研究者たち、特にGoogleのDeepMindでは、この分野で重要な研究が行われています。
Qが何であれ、それが人工一般知能に至る決定的なブレイクスルーであるとは私は懐疑的です。確かに、それが人類にとって脅威だとは思いません。しかし、一般的な推論能力を持つAIに向けた重要な一歩である可能性はあります。
この記事では、AI研究のこの重要な分野についてのガイド付きツアーを提供し、数学の問題に特化して設計されたステップバイステップの推論技術が、より広範な応用を持つ可能性がある理由を説明します。
ステップバイステップで推論する力
以下の数学の問題を考えてみてください:
ジョンはスーザンにリンゴを5個渡し、その後さらに6個渡しました。スーザンはリンゴを3個食べ、チャーリーに3個渡しました。彼女は残りのリンゴをボブに渡し、ボブは1個食べました。ボブは自分のリンゴの半分をチャーリーに渡しました。ジョンはチャーリーにリンゴを7個渡し、チャーリーは自分のリンゴの2/3をスーザンに渡しました。スーザンはチャーリーにリンゴを4個渡しました。チャーリーは今、何個のリンゴを持っていますか?
読み進める前に、自分で問題を解いてみてください。待っています。
私たちの多くは、小学校で基本的な数学の事実を暗記しました。例えば、5+6=11です。だから、問題が「ジョンがスーザンにリンゴを5個渡し、その後さらに6個渡した」と言っているだけなら、一目でスーザンが11個のリンゴを持っているとわかります。
しかし、もっと複雑な問題では、私たちのほとんどは紙や頭の中で逐次計算をしながら問題を解いていきます。まず5+6=11を足し、次に11-3=8、その後8-3=5と続けます。ステップバイステップで考えることで、最終的に正しい答えである8にたどり着きます。
同じトリックが大規模言語モデルにも有効です。2022年1月の有名な論文で、Googleの研究者たちは、大規模言語モデルが一度に一つのステップを推論するように促されると、より良い結果を生み出すことを指摘しました。以下はその論文からの重要なグラフィックです:

この論文は「ゼロショット」プロンプトが一般的になる前に公開されたため、モデルに例となる解答を与えてプロンプトしました。左側の列では、モデルが最終的な答えに直接飛びつくように促されていますが、間違った答えになっています。右側では、モデルが一度に一つのステップを推論するように促され、正しい答えを出しています。Googleの研究者たちは、この手法を「思考の連鎖プロンプト」と名付け、今日でも広く使用されています。
もしあなたが私たちの7月の記事で大規模言語モデルを説明したものを読んだなら、なぜこれが起こるのか推測できるかもしれません。
大規模言語モデルにとって、「five」や「six」のような数字はトークンであり、「the」や「cat」と変わりません。LLMは、5+6=11というトークンの並び(および「five and six make eleven」のような変形)が訓練データに何千回も登場するため、5+6=11を学びます。しかし、LLMの訓練データには、((5+6-3-3-1)/2+3+7)/3+4=8のような長い計算の例は含まれていない可能性が高いです。したがって、言語モデルにこの計算を一度に行うように求められた場合、混乱して間違った答えを出す可能性が高くなります。
別の見方をすると、大規模言語モデルには5+6=11のような中間結果を保存するための外部の「スクラッチスペース」がありません。思考の連鎖による推論は、LLMが自分の出力をスクラッチスペースとして効果的に使用することを可能にします。これにより、複雑な問題をモデルの訓練データにおいて例と一致する可能性が高い小さなステップに分解することができます。
より難しい数学の問題に取り組む
Googleが思考の連鎖プロンプトに関する論文を発表する数ヶ月前、OpenAIは8,500の小学校レベルの数学の言葉の問題(GSM8Kと呼ばれる)のデータセットと、それらを解決するための新しい技術を説明する論文を発表しました。単一の答えを生成する代わりに、OpenAIはLLMに100の思考の連鎖の答えを生成させ、検証者と呼ばれる第二のモデルを使用して各答えを評価します。これら100の回答の中から、システムは最も高い評価を受けた答えを返します。
検証者モデルの訓練が、最初にLLMに正しい回答を生成させる訓練と同じくらい難しいと思うかもしれませんが、OpenAIのテストはそうではないことを示しました。OpenAIは、小さなジェネレーターと小さな検証者を組み合わせることで、単独で30倍のパラメーターを持つはるかに大きなジェネレーターと同じくらいの結果を生み出すことができることを発見しました。
2023年5月の論文は、この分野でのOpenAIの作業に関する更新情報を提供しました。OpenAIは小学校レベルの数学を超えて、より挑戦的な問題を含むデータセット(MATHと呼ばれる)で作業を進めました。そして、検証者に全体の答えを評価させる代わりに、OpenAIは今や検証者に論文からのこのグラフィックに示されるように、各ステップを評価させる訓練をしています:

各ステップには緑のスマイリーフェイスがあり、解決策が正しい方向に進んでいることを示しています。最終ステップでモデルが「So x=7」と結論づけ、赤いフラウニーフェイスを得るまでです。
この論文の結論は、推論プロセスの各ステップで検証者を使用することが、最後まで待って全体の解決策を検証するよりも良い結果をもたらすことでした。
このステップバイステップの検証技術の大きな欠点は、自動化が難しいことです。MATHのトレーニングデータには各質問の正解が含まれていたため、モデルが正しい結論に達したかどうかを自動的にチェックするのは簡単でした。しかし、OpenAIは中間ステップを自動的に検証する良い方法を持っていませんでした。その結果、同社は75,000の解決策にわたる800,000ステップに対するフィードバックを提供する人間を雇うことになりました。
解決策を探す

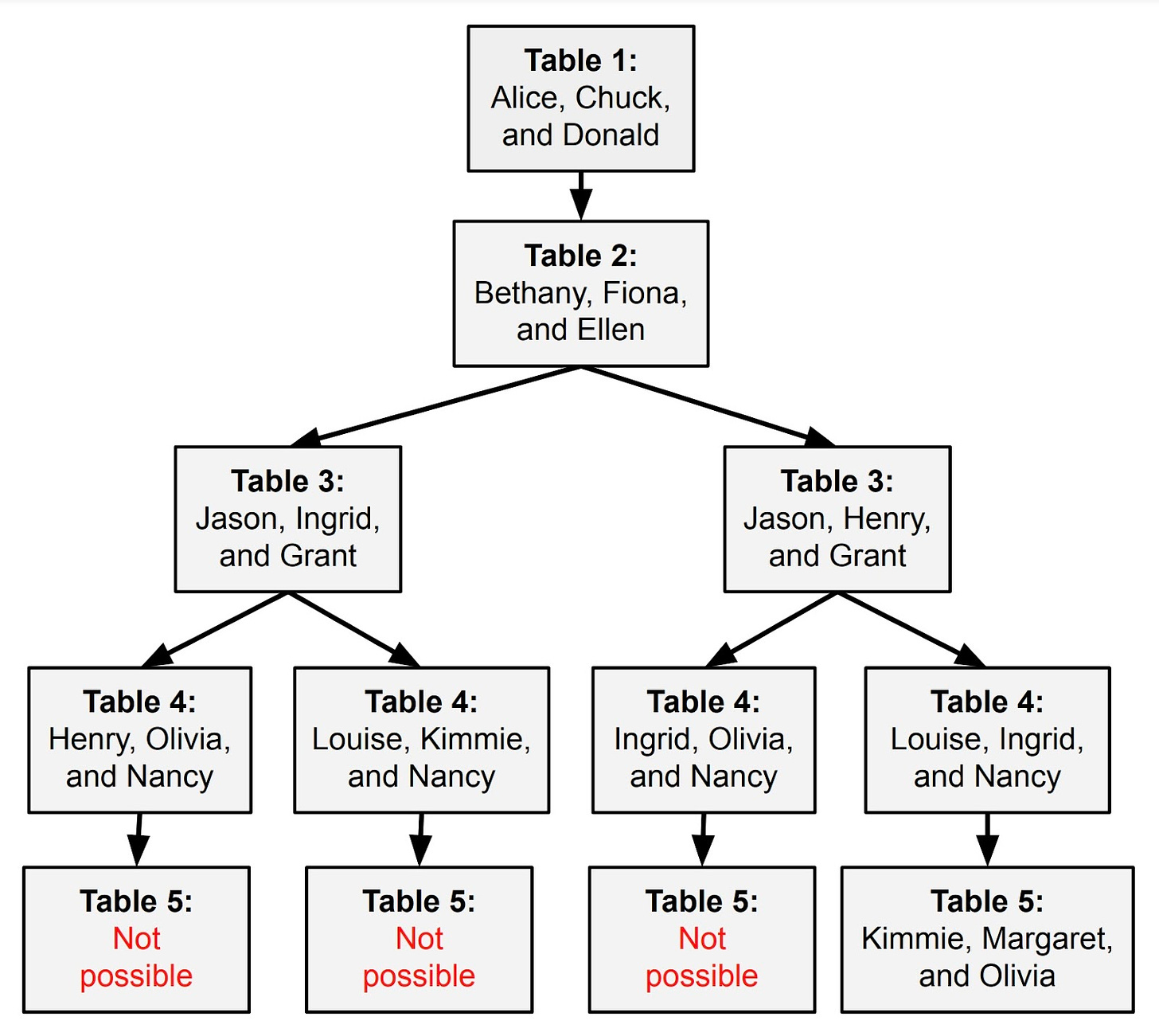
GSM8KおよびMATHデータセットの問題は、ステップバイステップで直接解決できます。しかし、すべての数学の問題がそのようなわけではありません。例としてこの問題を考えてみてください:
あなたは、各テーブルに3人のゲストがいる5つのテーブルで結婚式のレセプションを計画しています。
アリスはベサニー、エレン、キミーと一緒に座りたくありません。
ベサニーはマーガレットと一緒に座りたくありません。
チャックはナンシーと一緒に座りたくありません。
フィオナはヘンリーやチャックと一緒に座りたくありません。
ジェイソンはベサニーまたはドナルドと一緒に座りたくありません。
グラントはイングリッド、ナンシー、オリビアと一緒に座りたくありません。
ヘンリーはオリビア、ルイーズ、マーガレットと一緒に座りたくありません。
ルイーズはマーガレットやオリビアと一緒に座りたくありません。
これらの好みをすべて尊重してゲストをどのように配置できますか?
このプロンプトをGPT-4に与えたとき、それはステップバイステップで問題を解決し始めました:
- テーブル1:アリス、チャック、ドナルド。
- テーブル2:ベサニー、フィオナ、エレン。
- テーブル3:ジェイソン、グラント、イングリッド。
しかし、4番目のテーブルに到達したとき、それは立ち往生しました。まだヘンリー、マーガレット、ルイーズを座らせていませんでした。彼らは一緒に座りたくなかったが、残っているテーブルは2つだけでした。
この場合、GPT-4が間違いを犯した特定のステップを指摘することはできません。最初の3つのテーブルに対しては合理的な選択をしました。ただ、これらの早い選択が、残りのゲストを座らせることを不可能にしてしまったのです。
これはコンピュータ科学者がNP困難問題と呼ぶものです。これを線形に解決する一般的なアルゴリズムはありません。可能な配置を試し、それが機能するかどうかを確認し、機能しない場合はバックトラックする必要があります。
GPT-4は、コンテキストウィンドウにテキストを追加することでこのバックトラッキングを行うことができますが、それはうまくスケールしません。より良いアプローチは、GPT-4に「バックスペースキー」を与えて、最後の推論ステップ、または潜在的には最後のいくつかのステップを削除し、再試行できるようにすることです。これが機能するためには、システムが既に試した組み合わせを追跡し、努力の重複を避ける方法も必要です。これにより、LLMは次のような可能性の木を探索できるようになるかもしれません:
5月に、プリンストン大学とGoogleのDeepmindの研究者たちは、Tree of Thoughtsと呼ばれるアプローチを提案する論文を発表しました。単一の推論チェーンで問題を解決しようとするのではなく、Tree of ThoughtsはLLMが異なる方向に「分岐する」一連の推論チェーンを体系的に探索することを可能にします。
研究者たちは、このアルゴリズムが従来の大規模言語モデルでは解決が困難だった特定の問題に対してうまく機能することを発見しました。これには、24のゲームと呼ばれる数学的なパズルだけでなく、創造的なライティングタスクも含まれます。
AlphaGoモデルについて
これまでOpenAIとDeepMindが公開してきた研究を通じて、大規模言語モデルが数学の言葉の問題をより上手に解けるようにするための努力について説明してきました。さて、ここで少し推測になりますが、この研究がどのような方向に進むかについて話しましょう。これについて内部情報は持っていませんが、どこを見ればいいのか分かっていれば、お茶の葉を読むのはそれほど難しくないと思います。
以前の10月に、ポッドキャスターのDwarkesh PatelがDeepMindの共同創設者でありチーフサイエンティストのShane Leggにインタビューし、同社が人工一般知能(AGI)を達成するための計画について話しました。Leggは、AGIに向けた重要なステップの一つとして、大規模言語モデルを可能な応答の木を探索する能力と組み合わせることが必要だと主張しました:
これらの基礎モデルはある種の世界モデルであり、本当に創造的な問題解決を行うためには、探索を始める必要があります。例えばAlphaGoや有名な37手目のようなものを考えると、それはどこから来たのでしょうか?それは人間のゲームのデータから来たのでしょうか?いいえ、そうではありません。それは、ある手が非常にありそうもないがあり得ると識別し、探索のプロセスを通じて、実際には非常に良い手であると理解することから来ました。ですから、本当の創造性を得るためには、可能性の空間を探索し、これらの隠された宝石を見つける必要があります。
Leggが「有名な37手目」と言及したのは、2016年のDeepMindのAlphaGoソフトウェアとトップランクの囲碁プレイヤーであるイ・セドルとの対局の第2局を指しています。多くの人間の専門家は当初、AlphaGoの37手目を間違いと見なしました。しかし、AlphaGoはそのゲームに勝利し、後の分析でそれが実際には強い手であったことが明らかになりました。
AlphaGoは、人間のプレイヤーが見逃していた囲碁に関する洞察を得ました。AlphaGoは、現在の盤面から数千の可能なゲームをシミュレートすることで、そのような洞察を得ました。コンピュータがすべての可能な手順を調べるにはあまりにも多すぎるため、AlphaGoはニューラルネットワークを使用して管理可能な範囲に保ちました。
一つのネットワーク、ポリシーネットワークと呼ばれるものは、最も有望な手を予測し、シミュレートされたゲームで「プレイアウト」する価値があるかどうかを判断しました。もう一つのネットワーク、バリューネットワークは、結果としての盤面が白または黒にとってより有利かどうかを推定しました。これらの推定に基づいて、AlphaGoはどの手を打つかを決定するために逆算しました。
Leggのポイントは、同様の種類の木探索が大規模言語モデルの推論能力を向上させる可能性があるということです。単に最も可能性の高いトークンを予測するだけでなく、大規模言語モデルは答えを選ぶ前に何千もの異なる応答を探索するかもしれません。実際、DeepMindのTree of Thoughtsの論文はこの方向への第一歩のように思えます。
先に見たように、OpenAIはジェネレータ(潜在的な解決策を生成する)と検証者(それらの解決策が正しいかどうかを推定する)を組み合わせて数学の問題を解決しようと試みました。ここにはAlphaGoとの明らかな類似点があります。AlphaGoにはポリシーネットワーク(潜在的な手を生成する)とバリューネットワーク(それらの手が有利な盤面につながるかどうかを推定する)がありました。
OpenAIのジェネレータと検証者ネットワークをDeepMindのTree of Thoughtsのコンセプトと組み合わせると、AlphaGoのように機能する言語モデルが得られ、AlphaGoの強力な推論能力の一部を持つかもしれません。
Qと呼ばれる理由
AlphaGoの前に、DeepMindは2013年にAtariビデオゲームで勝つためのニューラルネットワークの訓練に関する論文を発表しました。各ゲームのルールを手作業でコーディングする代わりに、DeepMindはネットワークに実際のAtariゲームをプレイさせ、試行錯誤によってそれらについて学びました。
DeepMindは、以前の強化学習技術であるQ-learningにちなんで、そのAtariソリューションをDeep Q-learningと名付けました。DeepMindのAtari AIには、Q関数と呼ばれる機能が含まれており、特定の動き(例えばジョイスティックを左右に押すなど)から得られる可能性のある報酬(例えば高得点)を推定しました。システムがAtariゲームをプレイすると、どのアクションが最良の結果をもたらすかをよりよく推定するために、そのQ関数を最適化しました。
DeepMindの2016年のAlphaGoの論文では、再びQの文字を使用して、AlphaGoのアクションバリュー関数(勝利につながる可能性がどれだけあるかを推定する関数)を示しました。
AlphaGoとDeepMindのAtariボットは、経験から学ぶという機械学習技術である強化学習の例でした。強化学習は、大規模言語モデルの台頭前にOpenAIの主要な焦点でもありました。例えば、2019年には、OpenAIは強化学習を使用して、ロボットの手が自分自身でルービックキューブを解くための訓練を行うことができました。
これらの背景から、Qが何であるかについて推測することができます:大規模言語モデルをAlphaGoスタイルの探索と組み合わせる努力であり、理想的にはこのハイブリッドモデルを強化学習で訓練することです。究極の目標は、言語モデルが難しい推論タスクで「自分自身と対戦する」ことによって改善する方法を見つけることです。
ここで重要な手がかりは、OpenAIが今年初めにコンピュータ科学者のNoam Brownを雇ったことです。Brownはカーネギーメロン大学で博士号を取得し、超人的なレベルでポーカーをプレイできる最初のAIを開発しました。その後、BrownはMetaに移り、DiplomacyをプレイするAIを構築しました。Diplomacyでの成功は他のプレイヤーとの同盟を形成することに依存しているため、強力なDiplomacy AIは戦略的思考と自然言語能力を組み合わせる必要があります。
これは、大規模言語モデルの推論能力を向上させようとする人にとって良いバックグラウンドのようです。
「私は何年もの間、ポーカーやDiplomacyのようなゲームでのAI自己対戦と推論について研究してきました」とBrownは6月にツイートしました。「これらの方法を本当に一般的なものにする方法を調査します。」AlphaGoとBrownのポーカーソフトウェアで使用された探索方法は、それら特定のゲームに特化していました。しかし、Brownは「もし一般的なバージョンを発見できれば、その利益は巨大になるでしょう。はい、推論は1000倍遅く、コストもかかるかもしれませんが、新しいがん治療薬のためにはどれだけの推論コストを払いますか?またはリーマン予想の証明のためには?」と予測しました。
BrownがQに取り組んでいると信じている人物の一人が、Brownが今年初めまで働いていたMetaのチーフAIサイエンティストであるYann LeCunです。
「Q*はOpenAIが計画を試みている可能性が高い」とLeCunは11月にツイートしました。「彼らはほぼNoam Brownをそのために雇いました。」
二つの大きな課題
科学者やエンジニアの周りで時間を過ごしたことがある人なら、彼らがホワイトボードを愛用していることに気づいているでしょう。私が大学院でコンピュータサイエンスを学んでいたとき、私たちは問題を解決するためにホワイトボードの周りに立ち、図や方程式を描きながら多くの時間を過ごしました。私がGoogleのニューヨークオフィスで夏のインターンをしたとき、そこには至る所にホワイトボードがありました。
ホワイトボードはこの種の作業に役立ちます。なぜなら、人々はしばしば難しい技術的問題をどう解決すればいいかわからない状態から始めるからです。彼らは潜在的な解決策を何時間もスケッチしては、それがうまくいかないことに気づくかもしれません。それから彼らは全てを消して、異なるアプローチで最初からやり直すかもしれません。または、彼らの解決策の最初の半分は理にかなっていると判断して、後半を消して異なる方向に進むかもしれません。
これは本質的に知的なツリー検索の一形態です:多くの可能な解決策を反復して、問題を実際に解決するように見えるものを見つけるまで。
OpenAIやDeepMindのような組織がLLMをAlphaGoスタイルの検索ツリーと組み合わせることに興奮している理由は、それがコンピュータに同じ種類の開かれた知的探求を行うことを可能にすることを期待しているからです。あなたは難しい数学の問題に取り組むLLMを開始し、寝て、次の朝起きると、それが何千もの可能な解決策を考慮して、いくつか有望なものを見つけたことに気づくかもしれません。
それは魅力的なビジョンですが、OpenAIはそれを現実にするために少なくとも二つの大きな課題を克服しなければなりません。
最初の課題は、大規模言語モデルが「自己対戦」に参加する方法を見つけることです。AlphaGoは自分自身とゲームをして、勝ったか負けたかから学びました。OpenAIは、ルービックキューブのソフトウェアがシミュレートされた物理環境で練習するようにしました。それは、シミュレートされたキューブが「解決された」状態になったかどうかに基づいて、どのアクションが役立つかを学ぶことができました。
夢は、同様のタイプの自動化された「自己対戦」によって、大規模言語モデルが推論スキルを向上させることです。しかし、これには特定の解決策が正しいかどうかを自動的にチェックする方法が必要です。システムが各回答の正確性をチェックするために人間が必要な場合、トレーニングプロセスは人々と競争するスケールに達することはありそうにありません。
2023年5月の論文時点で、OpenAIはまだ数学の解決策の正確性をチェックするために人間を雇っていました。したがって、ここで突破口があったとしたら、それは過去数ヶ月の間に起こったはずです。
学習というダイナミックなプロセス
私は、二つ目の課題をより根本的なものと見ています:一般的な推論アルゴリズムには、可能な解決策を探索する中で即座に学習する能力が必要です。
誰かがホワイトボードで問題を解決しようとしているとき、彼らは単に可能な解決策を機械的に繰り返すだけではありません。人がうまくいかない解決策を試すたびに、彼らはその問題について少し学びます。彼らは推論しているシステムの精神的モデルを改善し、どのような解決策がうまくいくかについての直感をより良く得ます。
言い換えれば、人間の精神的な「ポリシーネットワーク」と「バリューネットワーク」は静的ではありません。私たちが問題に費やす時間が長ければ長いほど、有望な解決策を考えることが上手くなり、提案された解決策がうまくいくかどうかを予測することが上手くなります。このリアルタイム学習の能力がなければ、私たちは本質的に無限の潜在的な推論ステップの空間で迷ってしまうでしょう。
対照的に、今日のほとんどのニューラルネットワークは、トレーニングと推論の間に厳格な分離を維持しています。AlphaGoが訓練された後、そのポリシーとバリューネットワークは固定されました—ゲーム中に変化しませんでした。それは囲碁にとっては問題ありません。なぜなら囲碁は十分に単純で、自己対戦中に可能なゲーム状況の全範囲を経験することが可能だからです。
しかし、現実の世界は囲碁の盤よりもはるかに複雑です。定義上、研究を行っている人は以前に解決されていない問題を解決しようとしているので、それはおそらく訓練中に遭遇した問題に密接に似ていることはないでしょう。
したがって、一般的な推論アルゴリズムには、推論プロセス中に得られた洞察が、同じ問題を解決しようとする際のモデルの後続の決定に情報を提供する方法が必要です。しかし、今日の大規模言語モデルは、コンテキストウィンドウを通じて完全に状態を維持しており、Tree of Thoughtsアプローチは、モデルが一つの枝から別の枝にジャンプする際にコンテキストウィンドウから情報を削除することに基づいています。
ここでの一つの可能な解決策は、木ではなくグラフを使用して検索することです。これは8月の論文で提案されたアプローチです。これにより、大規模言語モデルは複数の「枝」から得られた洞察を組み合わせることができるかもしれません。
しかし、私は、本当に一般的な推論エンジンを構築するには、より根本的なアーキテクチャの革新が必要になると疑っています。必要なのは、言語モデルが訓練データを超えた新しい抽象概念を学び、これらの進化する抽象概念が可能な解決策の空間を探索する際のモデルの選択に影響を与える方法です。
これが可能であることは、人間の脳がそれを行っているからです。しかし、OpenAI、DeepMind、または他の誰かがシリコンでそれを行う方法を見つけるまでには、しばらく時間がかかるかもしれません。
まとめ:Q*プロジェクトが私たちの未来にもたらすもの
Q*プロジェクトは、強化学習と大規模言語モデルを組み合わせた先進的な取り組みであり、人工知能の分野における次の大きな飛躍を目指しています。このプロジェクトの核心は、AlphaGoのような探索アルゴリズムと自己対戦の概念を活用し、AIが新しい問題解決手法を自ら学習し、改善する能力を持つことです。
Q*プロジェクトが成功すれば、AIは囲碁の盤面を超えた複雑な現実世界の問題に対応できるようになります。これにより、AIは未解決の科学的課題や社会的問題に取り組む際に、人間の研究者や専門家を補完し、時には超える可能性を秘めています。
私たちの未来において、Q*プロジェクトは以下のような影響をもたらすと期待されます:
- 新しい発見とイノベーション: Qによって訓練されたAIは、がん治療薬の開発やリーマン予想のような数学的問題の解決など、人類にとっての大きな進歩に貢献するかもしれません。
- 高度な推論能力: AIは、複雑な戦略的思考を必要とするゲームや現実世界のシナリオで、高度な推論を行うことができるようになります。
- 自動化と効率化: Qプロジェクトは、多くの業務やプロセスを自動化し、人間の労働を軽減することで、より創造的な作業に集中できるようになります。
- 教育と学習の進化: 教育分野において、Qは個々の学習者に合わせたカスタマイズされた学習経路を提供し、効果的な学習体験を実現します。
Qプロジェクトは、AIが単なるツールから真のパートナーへと進化する過程を加速させるかもしれません。しかし、その実現には、AIの訓練と推論のプロセスを再考し、AIが新しい抽象概念を学び取り、それを基に決定を下す能力を持たせる必要があります。人間の脳がそれを行うように、AIもまた、私たちの未来を形作るための新しい道を切り開くことができるのです。
